

Application of Machine Learning Algorithms to Identify Problematic Nuclear Data
Nuclear Science and Engineering / Volume 195 / Number 12 / December 2021 / Pages 1265-1278
Technical Paper / dx.doi.org/10.1080/00295639.2021.1935102

Articles are hosted by Taylor and Francis Online.
In this work, we aim to show that machine learning algorithms are promising tools for the identification of nuclear data that contribute to increased errors in transport simulations. We demonstrate this through an application of a machine learning algorithm (Random Forest) to the Whisper/MCNP6 criticality validation library to identify nuclear data that are associated with an increase of the bias (simulated-experimental 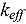 ) in the calculations. Specifically, the
) in the calculations. Specifically, the 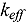 sensitivity profiles (with respect to nuclear data) of
sensitivity profiles (with respect to nuclear data) of 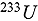 solution benchmarks are used to predict the bias, and SHapley Additive exPlanations (SHAP) are used to explain how the sensitivities are related to the predicted bias. The SHAP values can be interpreted as sensitivity coefficients of the machine learning model to the
solution benchmarks are used to predict the bias, and SHapley Additive exPlanations (SHAP) are used to explain how the sensitivities are related to the predicted bias. The SHAP values can be interpreted as sensitivity coefficients of the machine learning model to the 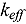 sensitivities that are used to make predictions of bias. Using the SHAP values, we can identify specific subsets of nuclear data that have the highest probability of influencing bias. We demonstrate the utility of this method by showing how SHAP values were used to identify an inconsistency in the
sensitivities that are used to make predictions of bias. Using the SHAP values, we can identify specific subsets of nuclear data that have the highest probability of influencing bias. We demonstrate the utility of this method by showing how SHAP values were used to identify an inconsistency in the 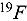 inelastic scattering nuclear data. The methodology presented here is not limited to transport problems and can be applied to other simulations if there are experimental measurements to compare against, simulations of those experimental measurements, and the ability to calculate sensitivities of the model output with respect to the data inputs.
inelastic scattering nuclear data. The methodology presented here is not limited to transport problems and can be applied to other simulations if there are experimental measurements to compare against, simulations of those experimental measurements, and the ability to calculate sensitivities of the model output with respect to the data inputs.