

Threadsafe Dynamic Neighbor Lists for Monte Carlo Ray Tracing
Nuclear Science and Engineering / Volume 194 / Number 11 / November 2020 / Pages 1009-1015
Technical Paper / dx.doi.org/10.1080/00295639.2020.1719765

Articles are hosted by Taylor and Francis Online.
Monte Carlo (MC) transport codes offer high-fidelity modeling of particle transport physics, but their high computational cost makes them impractical for many applications. For some applications such as multiphysics and depletion that use finely discretized geometries, a large portion of this computational cost is attributable to ray tracing. Neighbor lists are a well-known method for accelerating ray-tracing calculations in a MC code, but despite their prevalence, little work has been published on the details of their implementation. The fine details can have a significant impact on performance, particularly when using shared-memory parallelism. This paper addresses these details of implementation with a discussion of different neighbor list schemes and their impact on software runtime.
Performance tests were run by using OpenMC on a pin-cell problem discretized with up to 200 axial regions. The results demonstrate that switching from surface-based to cell-based neighbor lists leads to a 10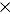 faster calculation rate for the most fine discretization. Furthermore, using a threadsafe shared-memory data structure results in a 20% faster calculation rate versus simple threadprivate neighbor lists. Results here show that a data structure that is contiguous in memory improves performance by only 1% to 2% over noncontiguous linked lists.
faster calculation rate for the most fine discretization. Furthermore, using a threadsafe shared-memory data structure results in a 20% faster calculation rate versus simple threadprivate neighbor lists. Results here show that a data structure that is contiguous in memory improves performance by only 1% to 2% over noncontiguous linked lists.