

A Cellwise Block-Gauss-Seidel Iterative Method for Multigroup SN Transport on a Hybrid Parallel Computer Architecture
Nuclear Science and Engineering / Volume 174 / Number 3 / July 2013 / Pages 209-226
Technical Paper / dx.doi.org/10.13182/NSE12-57

Articles are hosted by Taylor and Francis Online.
A Fourier analysis is conducted in two-dimensional (2-D) geometry for the discrete ordinates (SN) approximation of the neutron transport problem solved with Richardson iteration (source iteration) using the cellwise block-Jacobi (bJ) and block-Gauss-Seidel (bGS) algorithms. The results of the Fourier analysis show that convergence of bJ can degrade, leading to a spectral radius 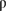 equal to 1, in problems containing optically thin cells. For problems containing cells that are optically thick, instead, tends to 0. Hence, in the optically-thick-cell regime, bJ is rapidly convergent even for scattering-dominated problems. Similar conclusions hold for bGS, except bGS approaches the asymptotic, thick-cell regime at convergence rates higher than bJ. Hence, we have implemented the bGS algorithm on the Roadrunner hybrid, parallel computer architecture. A compute node of this massively parallel machine comprises AMD Opteron cores that are linked to a Cell Broadband Engine (Cell/B.E.). LAPACK routines have been ported to the Cell/B.E. in order to make use of its parallel synergistic processing elements (SPEs). The bGS algorithm is based on the LU factorization and solution of a linear system that couples the fluxes for all SN angles and energy groups on a mesh cell. For every cell of a mesh that has been parallel decomposed on the higher-level Opteron processors, a linear system is transferred to the Cell/B.E. and the parallel LAPACK routines are used to compute a solution, which is then transferred back to the Opteron, where the rest of the SN transport computations take place. Compared to standard parallel machines, a one-hundred-fold speedup of the bGS was observed on Roadrunner. Numerical experiments with strong and weak parallel scaling demonstrate that the bGS method is viable and compares favorably to full parallel transport sweeps (FPS) on 2-D unstructured meshes when it is applied to optically thick, multimaterial problems. Specifically, the strong parallel efficiency of accelerated bGS on Roadrunner can achieve 73% at 512 processors, compared with 32 processors, while efficiency is 34% for the (Opteron-only) implementation of FPS. The weak parallel efficiency of bGS is 58% while it reaches 10% for FPS. As expected, however, bGS is not as efficient as FPS in optically thin problems.
equal to 1, in problems containing optically thin cells. For problems containing cells that are optically thick, instead, tends to 0. Hence, in the optically-thick-cell regime, bJ is rapidly convergent even for scattering-dominated problems. Similar conclusions hold for bGS, except bGS approaches the asymptotic, thick-cell regime at convergence rates higher than bJ. Hence, we have implemented the bGS algorithm on the Roadrunner hybrid, parallel computer architecture. A compute node of this massively parallel machine comprises AMD Opteron cores that are linked to a Cell Broadband Engine (Cell/B.E.). LAPACK routines have been ported to the Cell/B.E. in order to make use of its parallel synergistic processing elements (SPEs). The bGS algorithm is based on the LU factorization and solution of a linear system that couples the fluxes for all SN angles and energy groups on a mesh cell. For every cell of a mesh that has been parallel decomposed on the higher-level Opteron processors, a linear system is transferred to the Cell/B.E. and the parallel LAPACK routines are used to compute a solution, which is then transferred back to the Opteron, where the rest of the SN transport computations take place. Compared to standard parallel machines, a one-hundred-fold speedup of the bGS was observed on Roadrunner. Numerical experiments with strong and weak parallel scaling demonstrate that the bGS method is viable and compares favorably to full parallel transport sweeps (FPS) on 2-D unstructured meshes when it is applied to optically thick, multimaterial problems. Specifically, the strong parallel efficiency of accelerated bGS on Roadrunner can achieve 73% at 512 processors, compared with 32 processors, while efficiency is 34% for the (Opteron-only) implementation of FPS. The weak parallel efficiency of bGS is 58% while it reaches 10% for FPS. As expected, however, bGS is not as efficient as FPS in optically thin problems.